Lösung 2: Sperrung einzelner Seiten über die robots.txt beheben
 Haben Sie alle Schritte beim Punkt „Lösung 1“ befolgt und die Webseite wurde dennoch nicht indexiert?
Haben Sie alle Schritte beim Punkt „Lösung 1“ befolgt und die Webseite wurde dennoch nicht indexiert?
Dann kann es sein, dass die Webseite von der Aufnahme in den Suchergebnissen ausgeschlossen wurde. Das kann manchmal unabsichtlich passieren. Sie können dieses Problem jedoch relativ schnell prüfen und beheben.
Um dem Google-Bot auf einer Webseite den Weg zu weisen, „kommunizieren“ Webentwickler durch bestimmte Codes mit dem Crawler. Diese werden an bestimmten Orten im Gesamtcode der Webseite platziert.
Vereinfacht gesagt finden Sie die Codes an diesen drei Stellen:
- der robots.txt
- dem Meta-Robots-Tag
- dem Canonical-Tag
An jedem dieser drei Orte könnte ein Code platziert sein, der dafür sorgt, dass die Webseite bei Google nicht richtig angezeigt wird. Daher schauen wir uns diese einmal genauer an.
Die robots.txt
 Die robots.txt ist eine Textdatei, die Sie im Root-Verzeichnis Ihres Webservers finden können.
Die robots.txt ist eine Textdatei, die Sie im Root-Verzeichnis Ihres Webservers finden können.
Diese Datei übermittelt Anweisungen an den Google-Bot, welche Bereiche der Webseite er sich ansehen darf und welche nicht.
Die robots.txt finden Sie in der Regel unter folgender URL (www.meinedomain.de tauschen Sie wieder durch die URL Ihrer Webseite aus):
www.meinedomain.de/robots.txt
Im Normalfall haben alle Webseiten eine robots.txt. Ganz selten kann es aber vorkommen, dass keine Datei vorhanden ist. Das ist nicht schlimm, in diesem Fall kann der Crawler also auch nicht durch die robots.txt blockiert werden.
Haben Sie die robots.txt auf Ihrem Server gefunden, können Sie nun nachprüfen, auf welche Inhalte der Google-Bot zugreifen darf und welche Inhalte blockiert sind.
Den folgenden Code sollten Sie unter keinen Umständen auf Ihrer robots.txt finden:
User-agent: *
Disallow: /
Dieser Befehl bedeutet, dass der Google-Crawler keinen Zugang zu Ihrer Startseite bekommt. Somit kann er auch die Unterseiten nicht erreichen. Haben Sie diesen Code in Ihrer Robots.txt gefunden, sollten Sie ihn ändern in:
User-agent: *
Allow: /
In der Regel sieht die robots.txt aber wie folgt aus:

Die erste Zeile bestimmt, welche Bots Zugriff auf die Seite haben. Mit dem Zeichen * erlauben Sie allen Bots den Zugriff und schließen keinen aus.
In der zweiten Zeile werden alle Inhalte aufgelistet, die die Bots nicht besuchen sollen.
In unserem Beispiel ist das das Unterverzeichnis /wp-admin/.
Auf das Verzeichnis /wp-admin/admin-ajax.php hat der Bot dennoch Zugriff. Dies haben wir in der dritten Zeile festgelegt.
Alle anderen Verzeichnisse wurden nicht explizit in der robots.txt erwähnt und können daher von den Google-Bots besucht und gelesen werden.
Die Datei enthält zusätzlich einen Hinweis auf die Sitemap der Webseite.
Möchten Sie die robots.txt bearbeiten, müssen Sie das nicht über den Server tun.
Nutzen Sie für Ihre Webseite ein CMS wie WordPress, TYPO3 oder Drupal, können Sie die robots.txt mithilfe des Plugins YOAST SEO bearbeiten.
Wie das geht, lesen Sie in der Anleitung von Kinsta zum Thema WordPress + robots.txt. Die Anleitung bezieht sich auf WordPress, in den anderen Systemen kann die Benutzeroberfläche ggf. etwas anders aussehen.
Ein kurze Anleitung für WordPress mit dem Yoast SEO-Plugin:
1. Klicken Sie in der linken Menüleiste im WordPress-Dashboard auf SEO > Werkzeuge. Wählen Sie dann den Datei-Editor aus.
2. Nun finden Sie ein Feld mit dem Code Ihrer robots.txt und können diese anpassen. Bestätigen Sie die Änderungen mit einem Klick auf „Speichere die Änderungen der robots.txt“.
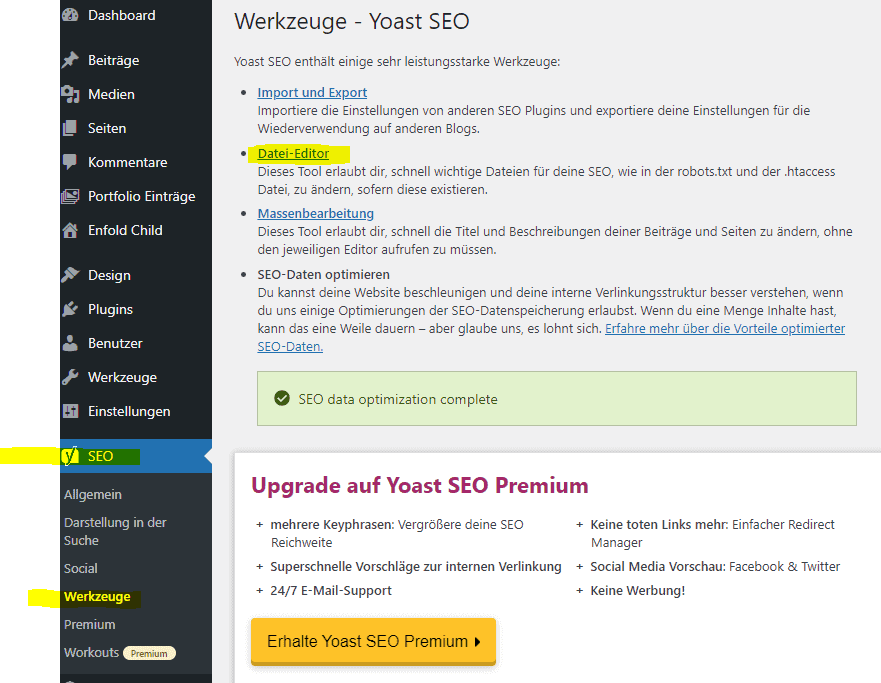
Möchten Sie das YOAST SEO Plugin nicht nutzen, gibt es auch weitere Plugins, die die Bearbeitung der robots.txt ermöglichen, zum Beispiel das Plugin WP Robots Txt.
Nachdem Sie das Plugin installiert und aktiviert haben, finden Sie in der WordPress-Menüleiste unter Einstellungen > Lesen ein Textfeld.
Dort können Sie die Anpassungen der robots.txt vornehmen.

Weitere Informationen und ausführliche Anleitungen zum Erstellen der robots.txt im FTP-Server oder mit der Hilfe von Plugins finden Sie in dem Blogartikel „WordPress Robots.txt Anleitung – was es ist und wie man es benutzt“ von Kinsta.
Der Meta-Robots-Tag
 Haben Sie in der robots.txt keinen Fehler gefunden oder diesen bereits behoben, aber die Seite wird immernoch nicht bei Google angezeigt?
Haben Sie in der robots.txt keinen Fehler gefunden oder diesen bereits behoben, aber die Seite wird immernoch nicht bei Google angezeigt?
In diesem Fall sehen Sie sich den Meta-Robots-Tag einmal genauer an. Dieser befindet sich anders als die robots.txt nicht in einer eigenen Datei. Er ist im Quellcode der Webseite im Headbereich zu finden.
Um ihn zu finden, können Sie also ganz einfach in den Quellcode Ihrer Seite schauen. Rufen Sie dafür Ihre Webseite auf und machen Sie einen Rechtsklick irgendwo auf der Seite. Wählen Sie nun „Seitenquelltext anzeigen“ aus.
Dies funktioniert auch durch einen Shortcut.
In den Browsern Chrome und Firefox verwenden Sie STRG/CMD + U, in Safari Alt + CMD + U. Anschließend öffnet sich ein neues Fenster mit dem Quelltext Ihrer Seite. Sie sehen nun den HTML Code, das Grundgerüst Ihrer Webseite.
Um nun den Meta-Robots-Tag zu finden, durchsuchen Sie den Quelltext mit STRG + F nach folgendem Suchwort:
meta name=“robots“
Der Browser markiert Ihnen nun die gesuchte Stelle im Quelltext. Sieht das Ergebnis wie folgt aus, haben Sie das Problem gefunden:
meta name=“robots“ content=“noindex,follow“
Dies bedeutet, dass die Webseite auf „noindex“ gesetzt wurde, Google also angewiesen wurde, diese Unterseite nicht in das Verzeichnis mit aufzunehmen.
Um die Seite indexieren zu lassen, muss der Tag auf „index,follow“ gesetzt werden.
Möchten Sie den Meta-Robots-Tag ändern, finden Sie hier weitere Informationen (Link). Anschließend wiederholen Sie Lösung 1, um Ihre Webseite indexieren zu lassen.
Das Canonical-Tag
 Auch das Canonical-Tag finden Sie im Quelltext Ihrer Webseite.
Auch das Canonical-Tag finden Sie im Quelltext Ihrer Webseite.
Es hat jedoch eine andere Funktion: Das Canonical-Tag wird genutzt, um Google auf eine Originalversion Ihrer Unterseite hinzuweisen. Dies kommt vor allem in Onlineshops zur Anwendung.
Ein Beispiel: Sie verkaufen auf Ihrer Webseite einen schicken weißen Turnschuh. Diesen finden die Nutzer in der Kategorie Sneaker.
Nun ist Sommerschlussverkauf und Sie bieten den Turnschuh nun ebenfalls in der Kategorie Sonderangebote an.
Für Google existiert die Unterseite für den Turnschuh nun doppelt.
Damit Google die Inhalte richtig einordnen kann und die Webseite nicht als Duplicate Content einstuft, verwenden wir den Canonical-Tag. Er verweist dann von der temporären Schlussverkaufs-Seite auf die dauerhafte Produktseite in der Kategorie Sneaker.
Das Canonical-Tag wird allerdings auch oft falsch verwendet. Daher sollten Sie bei Indexierungsproblemen prüfen, wie die Canonical-Tags auf Ihrer Webseite aussehen.
Dies können Sie über den gleichen Weg wie für den Meta-Robots-Tag testen. Rufen Sie den Quelltext Ihrer Webseite auf (Rechtsklick auf Ihre Webseite und „Seitenquelltext anzeigen“ wählen) und suchen Sie per Suchfunktion über STRG + F diesmal nach:
link rel=“canonical“ oder einfach nur „canonical“
Sollten Sie nichts finden, ist das kein Problem. Das bedeutet schlicht, dass auf dieser Unterseite kein Canonical-Tag gesetzt wurde. Der Tag kann den Bot also auch nicht blockieren.
Finden Sie das Tag, ist nach href=“…….“ die URL der Unterseite zu sehen, die Google als Originalseite angezeigt wird. Ist diese URL fehlerhaft, muss sie korrigiert werden.
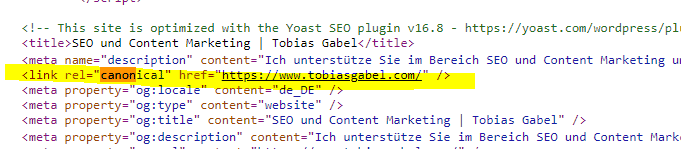
In der Abbildung sehen Sie den Quelltext für tobiasgabel.com. Das Canonical-Tag ist vorhanden und verweist auf die Seite, die wir aufgerufen haben. Hier liegt also kein Fehler vor.
Mehr Informationen zu Canonical-Tags finden Sie im Wiki von Ryte (Link).



 Sie können sich den Google Index wie ein Verzeichnis oder ein Glossar für Webseiten vorstellen.
Sie können sich den Google Index wie ein Verzeichnis oder ein Glossar für Webseiten vorstellen.

 Manche Webseiteninhalte werden durch die SafeSearch-Funktion von Google automatisch ausgeblendet.
Manche Webseiteninhalte werden durch die SafeSearch-Funktion von Google automatisch ausgeblendet. Ist Ihre Seite neu oder haben Sie erst kürzlich die Indexierung beantragt?
Ist Ihre Seite neu oder haben Sie erst kürzlich die Indexierung beantragt? Grundsätzlich wird Ihre Webseite in den Suchergebnissen angezeigt, wenn Sie spezifisch nach einer bestimmten Unterseite suchen, ist diese jedoch nicht auffindbar?
Grundsätzlich wird Ihre Webseite in den Suchergebnissen angezeigt, wenn Sie spezifisch nach einer bestimmten Unterseite suchen, ist diese jedoch nicht auffindbar? Wird Ihre Webseite zu einem relevanten Suchbegriff nicht in den Suchergebnissen gefunden, oder nur auf einer der hinteren Ergebnisseiten, ist das fast so, als würde die Seite gar nicht existieren.
Wird Ihre Webseite zu einem relevanten Suchbegriff nicht in den Suchergebnissen gefunden, oder nur auf einer der hinteren Ergebnisseiten, ist das fast so, als würde die Seite gar nicht existieren.

 Es gibt zahlreiche Gründe, weswegen Ihre Webseite bei Google nicht in den Top 10 gelistet ist.
Es gibt zahlreiche Gründe, weswegen Ihre Webseite bei Google nicht in den Top 10 gelistet ist. Nachfolgend schauen wir uns an, was Sie tun können, wenn die Seite von Google nicht richtig indexiert wird.
Nachfolgend schauen wir uns an, was Sie tun können, wenn die Seite von Google nicht richtig indexiert wird. Ist Ihre Webseite noch gar nicht im Verzeichnis von Google aufgenommen worden, gibt es eine einfache und verlässliche Lösung für dieses Problem.
Ist Ihre Webseite noch gar nicht im Verzeichnis von Google aufgenommen worden, gibt es eine einfache und verlässliche Lösung für dieses Problem.
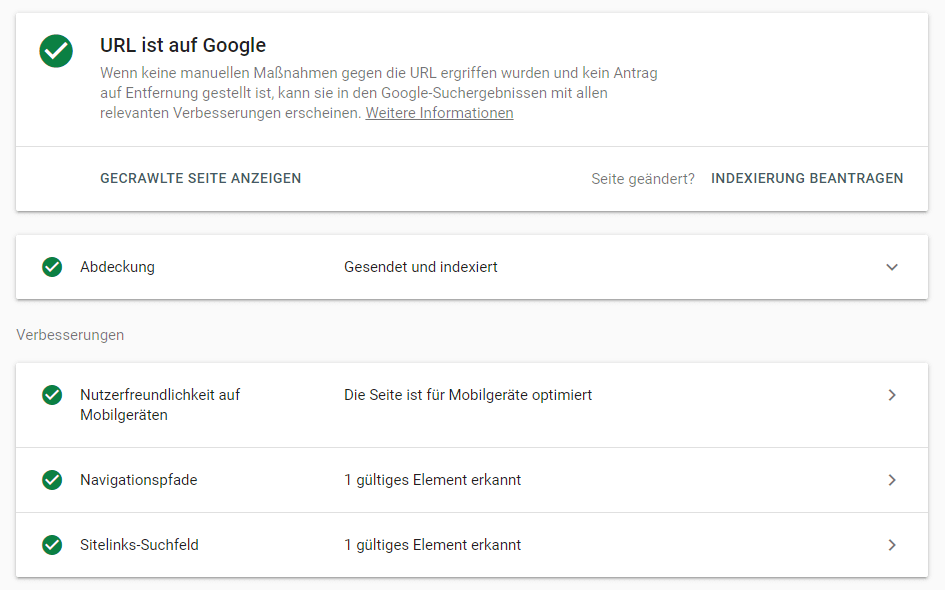


 Wie Sie den Google-Bot am besten durch Ihre Webseite lenken, ist je nach CMS unterschiedlich. In diesem Artikel konzentrieren wir uns auf das CMS von WordPress.
Wie Sie den Google-Bot am besten durch Ihre Webseite lenken, ist je nach CMS unterschiedlich. In diesem Artikel konzentrieren wir uns auf das CMS von WordPress.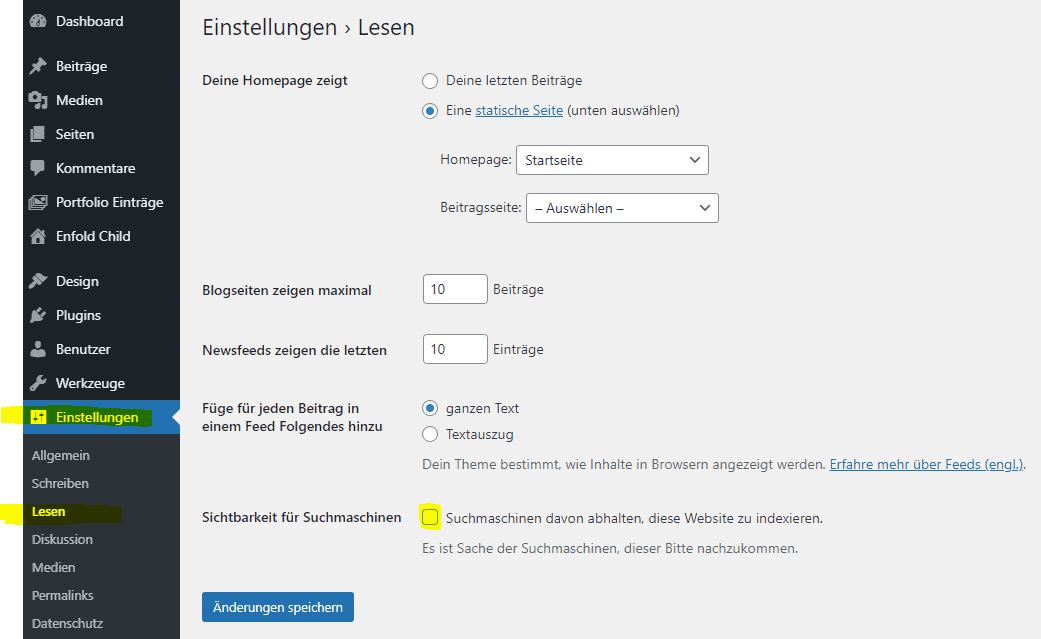
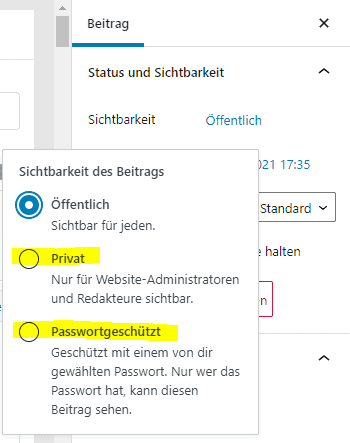
 Eventuell haben Sie absichtlich oder unabsichtlich eine URL über die Search Console aus dem Verzeichnis von Google entfernt. Sollte dies der Fall sein, lässt sich dieser Schritt wieder rückgängig machen.
Eventuell haben Sie absichtlich oder unabsichtlich eine URL über die Search Console aus dem Verzeichnis von Google entfernt. Sollte dies der Fall sein, lässt sich dieser Schritt wieder rückgängig machen.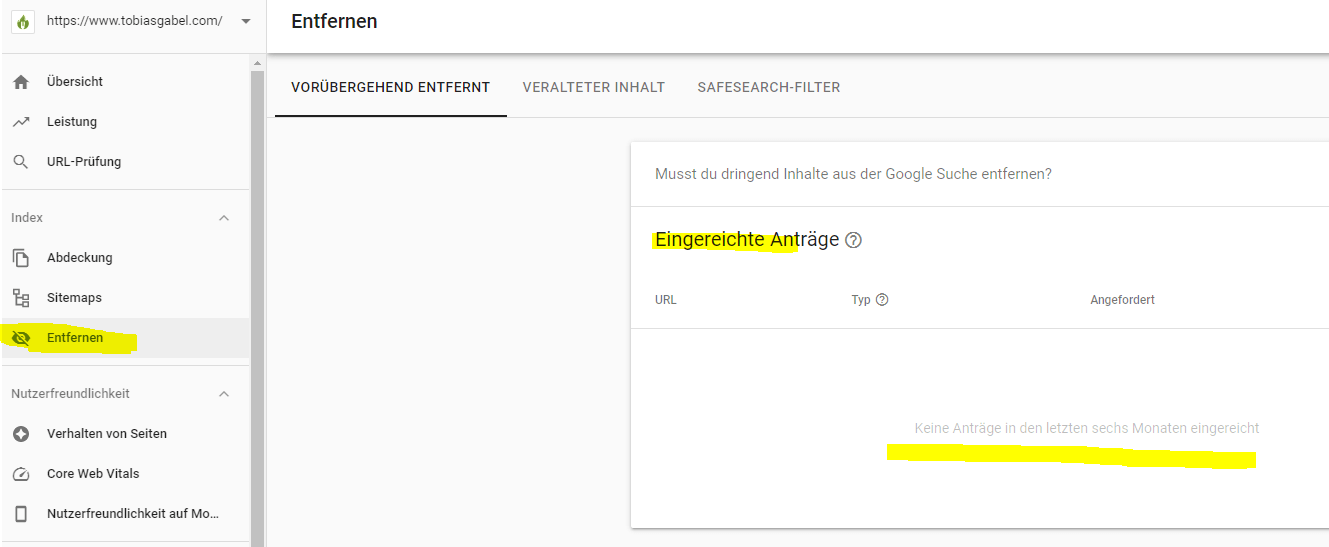
 Im Anschluss möchte ich Ihnen noch ein paar allgemeine Tipps rund um das Google-Ranking und die Indexierung in der Suchmaschine mitgeben.
Im Anschluss möchte ich Ihnen noch ein paar allgemeine Tipps rund um das Google-Ranking und die Indexierung in der Suchmaschine mitgeben. Um Google beim Finden und Einordnen Ihrer Inhalte zu unterstützen, können Sie die folgenden Maßnahmen anwenden:
Um Google beim Finden und Einordnen Ihrer Inhalte zu unterstützen, können Sie die folgenden Maßnahmen anwenden: Um es dem Google-Crawler zu erleichtern, die Inhalte Ihrer Webseite zu interpretieren und einzuordnen, gibt es mehrere Aspekte:
Um es dem Google-Crawler zu erleichtern, die Inhalte Ihrer Webseite zu interpretieren und einzuordnen, gibt es mehrere Aspekte: Schnelle Webseiten sind für den Nutzer angenehmer zu verwenden.
Schnelle Webseiten sind für den Nutzer angenehmer zu verwenden. Das bedeutet, dass Ihre Seite auf allen Bildschirmen bequem abgerufen werden kann, egal ob der Nutzer sie auf dem Handy, Tablet oder Desktop-Bildschirm betrachtet.
Das bedeutet, dass Ihre Seite auf allen Bildschirmen bequem abgerufen werden kann, egal ob der Nutzer sie auf dem Handy, Tablet oder Desktop-Bildschirm betrachtet. Installieren Sie für Ihre Webseite ein SSL-Zertifikat. So ist die Verbindung zwischen Nutzer und der Webseite verschlüsselt und Nutzer können ohne Sicherheitsbedenken Daten übermitteln (zum Beispiel über Kontaktformulare).
Installieren Sie für Ihre Webseite ein SSL-Zertifikat. So ist die Verbindung zwischen Nutzer und der Webseite verschlüsselt und Nutzer können ohne Sicherheitsbedenken Daten übermitteln (zum Beispiel über Kontaktformulare). Ihr Content kann aus mehreren Gründen dafür sorgen, dass Sie mit Ihrer Webseite bei Google nicht auf den Top-Plätzen erscheinen.
Ihr Content kann aus mehreren Gründen dafür sorgen, dass Sie mit Ihrer Webseite bei Google nicht auf den Top-Plätzen erscheinen. Es gibt keine generelle Faustregel, wie viele Zeichen oder Wörter ein Beitrag haben muss.
Es gibt keine generelle Faustregel, wie viele Zeichen oder Wörter ein Beitrag haben muss. Cloaking ist die Bezeichnung für ein Verfahren, bei dem menschliche Nutzer andere Inhalte zu sehen bekommen als die Suchmaschinen.
Cloaking ist die Bezeichnung für ein Verfahren, bei dem menschliche Nutzer andere Inhalte zu sehen bekommen als die Suchmaschinen. Backlink-Aufbau ist eine gute Möglichkeit das Ranking zu verbessern – wenn es richtig gemacht wird.
Backlink-Aufbau ist eine gute Möglichkeit das Ranking zu verbessern – wenn es richtig gemacht wird. Gerade nach einem Relaunch der Webseitenstruktur verlieren viele Webseiten an Sichtbarkeit.
Gerade nach einem Relaunch der Webseitenstruktur verlieren viele Webseiten an Sichtbarkeit. Erscheint Ihre Webseite auf einmal nicht mehr in den Suchergebnissen, kann dies auch eine Folge einer Abstrafung durch Google sein.
Erscheint Ihre Webseite auf einmal nicht mehr in den Suchergebnissen, kann dies auch eine Folge einer Abstrafung durch Google sein. Die Nutzersignale einer Webseite sind weiterhin von großem Interesse für Google um die Qualität einschätzen zu können. Dazu werden Kennzahlen gemessen, wie zum Beispiel die Click-Through-Rate (CTR) oder die Verweildauer. Optimieren Sie in Zukunft auch diese Werte, um mit Ihrer Webseite wettbewerbsfähig zu bleiben.
Die Nutzersignale einer Webseite sind weiterhin von großem Interesse für Google um die Qualität einschätzen zu können. Dazu werden Kennzahlen gemessen, wie zum Beispiel die Click-Through-Rate (CTR) oder die Verweildauer. Optimieren Sie in Zukunft auch diese Werte, um mit Ihrer Webseite wettbewerbsfähig zu bleiben. Nichts gefunden? Sie konnten keine Lösung finden?
Nichts gefunden? Sie konnten keine Lösung finden?